Homework 4: Variational Auto-Encoding for Sign Types
Start on July 17, 2023 | Due on July 31, 2023
Getting Started
If you have already cloned my homework repository nlp-class-hw for
previous homeworks then go into that directory and update the directory:
git pull origin/master
cd nlp-class-hw/signvae
If you don’t have that directory anymore then simply clone the repository again:
git clone https://github.com/anoopsarkar/nlp-class-hw.git
Clone your own repository from GitLab if you haven’t done it already:
git clone git@csil-git1.cs.surrey.sfu.ca:USER/advnlpclass-1234-g-GROUP.git
Note that the USER above is the SFU username of the person in
your group that set up the GitLab repository.
Then copy over the contents of the signvae directory into your
hw4 directory in your repository.
Set up the virtual environment:
python3.10 -m venv venv
source venv/bin/activate
pip3 install -r requirements.txt
You must use Python 3.10 (or later) for this homework.
Note that if you do not change the requirements then after you have
set up the virtual environment venv you can simply run the following
command to get started with your development for the homework:
source venv/bin/activate
The Challenge
Imagine that you are an archaeologist from the far future, when the English language has been totally forgotten. You have just uncovered a stash of handwritten English manuscripts which you are trying to decipher. Unfortunately, you don’t know the English alphabet, and so you aren’t able to tell whether any two symbols represent the same letter. Your task is to recover the English alphabet by clustering the characters from these manuscripts.
The Baseline
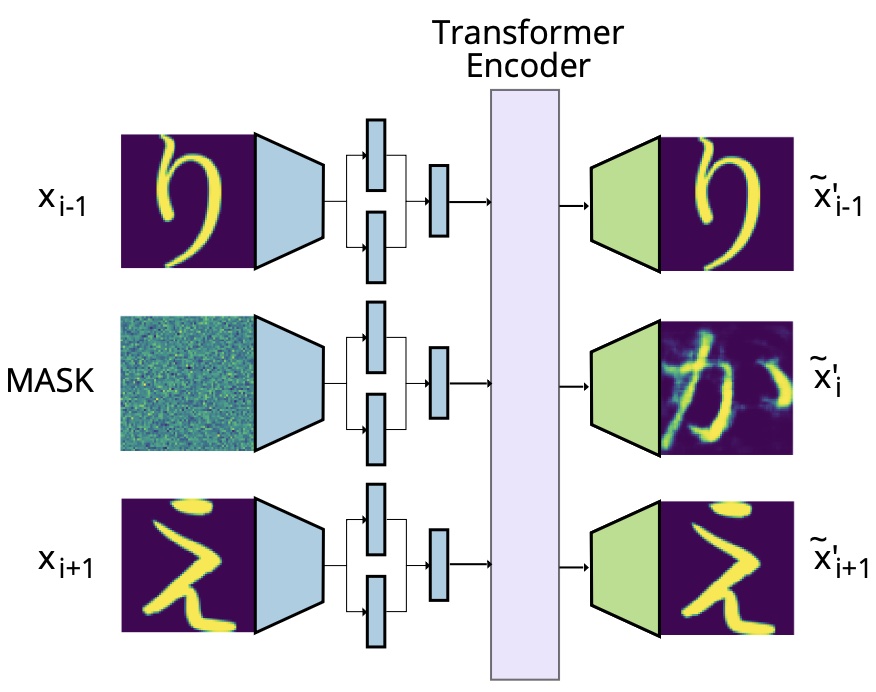
You are given a partial implementation of the character clustering model from Born et al. 2023. However, we have removed the variational autoencoder (VAE), which encodes images as dense vectors and decodes those vectors to recover the original images. You must complete the model by finishing the partial implementations of kld() and vae_loss() in the class VAE provided in default.py.
Extensions to the Baseline
The VAECluster.forward() method (in model/__init__.py) returns a Python dict named results which contains sequences of features describing the images which the model has seen. For example, results["vae_z"] contains the code $z$ computed for each input image, and results["gen_vae_self"] contains the images that have been reconstructed from these codes.
By default, check.py evaluates your output by clustering the vae_z features. You can pass any key from the results dictionary to check.py in order to cluster on that feature instead:
python3 check.py gen_vae_self # will cluster the reconstructed images instead of the VAE codes
Once you have completed the basic model implementation, you should try to improve your clustering accuracy by adding additional features to the results dictionary and clustering on those features. You may use any features you think will be helpful. Possible ideas include:
- internal layers, self-attention scores, or other features from the Transformer in
VAECluster.txr - concatenating
vae_zwith another feature such astxr_z(the code output by the Transformer LM) - 2D cross-correlations between images
- features from the
pseudolabelsorcentroidsarrays used to compute the pseudolabel loss (additional details here)
Check Your Accuracy
To train the model and save the outputs on the test set, run:
python3 train.py
If you have a CUDA-capable GPU, you can train on GPU using:
python3 train.py --cuda
To check your accuracy on the test set:
python3 check.py
Or, to check the accuracy from clustering on a specific feature (e.g. txr_z):
python3 check.py txr_z
The output score is the V-measure of your clustering compared to the ground truth.
Additional Tools
inspect.ipynb contains sample code for inspecting the model inputs and outputs. You may wish to use this to check whether your model is correctly recovering the character images.
Submit your homework on Coursys
Once you are done with your homework submit all the relevant materials to Coursys for evaluation.
Create output.npz
Once you have trained a model and saved the outputs on the test set, create the output.npz for Coursys by running:
python3 zipout.py
By default, this will zip the vae_z feature vectors. If you have added a new feature to the results dictionary, and would like to be evaluated on that feature instead, please specify the feature name when running zipout.py:
python3 zipout.py your_feature_name
Copy the output.npz file to output.zip to upload to Coursys. You will need a .zip suffix to pass the Coursys check on valid filename.
Pre-trained Model
A pre-trained mnodel is available for use in data/trained.pt and data/trained.config.
Data files
The data files for this homework are in data/bin
- Training data:
data/bin/train.npz - Test data:
data/bin/test.npz
Default solution
The default solution is used by main.py and is available in the file default.py. You should replace it with your own answer/vae.py as a replacement.
Submit your homework on Coursys
Once you are done with your homework submit all the relevant materials to Coursys for evaluation.
Create output.zip
Create output.zip using the instructions above and upload to Coursys (remember to copy output.npz to output.zip).
Create source.zip
To create the source.zip file for upload to Coursys do:
python3 zipsrc.py
You must have the following files or zipsrc.py will complain about it:
answer/vae.py– this is the file containing the implementations of functionskld()andvae_loss()in the classVAE.answer/signvae.ipynb– this is the iPython notebook that will be your write-up for the homework.
Each group member should write about what they did for this homework in the Python notebook.
Upload to Coursys
Go to Homework 4 on Coursys and do a group submission:
- Upload
output.zipandsource.zip - Make sure you have documented your approach in
answer/signvae.ipynb. - Make sure each member of your group has documented their contribution to this homework in the Python notebook.
Grading
The grading is split up into the following components:
- test scores (see Table below)
- iPython notebook write-up
- Make sure that you are not using any external data sources in your solution.
- Make sure you have implemented the fine-tuning model improvements yourself without using external libraries.
- Check if each group member has written about what they did in the Python notebook.
Your score should be equal to or greater than the score listed for the corresponding marks.
| V-measure(test) | Marks | Grade |
| 0.0 | 0 | F |
| 0.10 | 55 | D |
| 0.40 | 60 | C- |
| 0.50 | 65 | C |
| 0.60 | 70 | C+ |
| 0.70 | 75 | B- |
| 0.83 | 80 | B |
| 0.87 | 85 | B+ |
| 0.88 | 90 | A- |
| 0.89 | 95 | A |
| 0.92 | 100 | A+ |
The score will be normalized to the marks on Coursys for the test scores.