
Code Generation with LLVM: Practice Problems
Clone the repository
The files below and other example programs are available in a git repository
You must have git and python (3.x) on your system. Once you’ve confirmed this, run this command:
git clone https://github.com/anoopsarkar/compilers-class-hw.git
If you have already cloned the repository earlier you can get the new homework files by going to the directory where you cloned the repository earlier and then doing:
# go to the directory where you did a git clone earlier
git pull origin master
Then go to the llvm-practice directory
cd /your-path-to/compilers-class-hw/llvm-practice
Installation
We will be using LLVM version 20.1.x for the homeworks in this course offering.
LLVM 20.1.x has already been installed in the CSIL Linux machines. You can use
this version on CSIL by using llvm-config in your makefile or using llvm-config on your
local machine LLVM installation.
/usr/shared/CMPT/faculty/anoop/llvm.
You can activate the following virtual environment to access the
right versions of the compiler toolchain by running: source
/usr/shared/CMPT/faculty/anoop/base/env745/bin/activate
You can also install LLVM on your own machine by following the links on this page:
http://llvm.org/releases/download.html
brew install llvm
then make sure that /usr/local/opt/llvm/bin is in your
$PATH shell variable.
Here is how to use the makefile in different environments:
- On CSIL Linux machines: use
make -f makefile.csil allafter you set your virtual environment - On your local macos or other installation: use
make all
Decaf standard library
The file decaf-stdlib.c contains the standard library for Decaf and it contains
the implementation of functions like print_int, read_int, etc.
Write a C or C++ program that uses the functions defined in decaf-stdlib.c.
For example, add these lines to a test C or C++ program and compile by linking
with decaf-stdlib.c:
int i = read_int();
print_string("this is a test:");
print_int(i);
print_string("\n");
We will link the Decaf standard library with the x86 assembly that will be generated using LLVM.
Hello World
LLVM is both a library for code generation and also a definition of an abstract assembly language which is used as an intermediate representation for code generation and code optimization that is machine independent.
LLVM assembly is converted into x86 machine code. The file helloworld.ll
contains a simple Hello, World program in LLVM assembly.
; Declare the string constant as a global constant.
; run the following command to run this LLVM assembly program:
; sh run-llvm-code.sh helloworld.ll
@LC0 = internal constant [13 x i8] c"hello world\0A\00"
; note how the newline character is inserted into the string
; External declaration of the puts function
declare i32 @puts(i8*)
; Definition of main function
define i32 @main() {
; Convert [13 x i8]* to i8*
; this is because the function puts takes a char* which is an i8* in LLVM
%cast = getelementptr [13 x i8], [13 x i8]* @LC0, i8 0, i8 0
; read up on getelementptr: http://llvm.org/docs/GetElementPtr.html
; Call puts function to write out the char* string to stdout.
call i32 @puts(i8* %cast)
ret i32 0
}
i8 is an 8-bit integer used by LLVM for ASCII characters. The puts function
takes an ASCII string and returns an integer return value of type i32.
Except for the getelementptr instruction the rest is easy to follow. The next
question explains the use of the getelementptr to access global constants.
The LLVM assembly file can be run directly using the lli command:
llvmconfig=llvm-config
lli_bin=`$llvmconfig --bindir`/lli
$lli_bin helloworld.ll
In this case we did not need to link with the Decaf standard library
since we do not use any of the functions in it, but when we implement
the Decaf compiler it will be easier to use the Decaf standard library
functions instead of a function like puts which take pointers as
arguments.
Using Decaf Library Functions
The following LLVM assembly code defines a function @add1 that adds
two integers and prints out the value followed by a newline.
declare void @print_int(i32)
declare void @print_string(i8*)
declare i32 @read_int()
; store the newline as a string constant
; more specifically as a constant array containing i8 integers
@.nl = constant [2 x i8] c"\0A\00"
define i32 @add1(i32 %a, i32 %b) {
entry:
%tmp1 = add i32 %a, %b
ret i32 %tmp1
}
define i32 @main() {
entry:
%tmp5 = call i32 @add1(i32 3, i32 4)
call void @print_int(i32 %tmp5)
; convert the constant newline array into a pointer to i8 values
; using getelementptr, arg1 = @.nl,
; arg2 = first element stored in @.nl which is of type [2 x i8]
; arg3 = the first element of the constant array
; getelementptr will return the pointer to the first element
%cast.nl = getelementptr [2 x i8], [2 x i8]* @.nl, i8 0, i8 0
call void @print_string(i8* %cast.nl)
ret i32 0
}
Save the above LLVM assembly to a file add.ll. Notice that it uses
the Decaf standard library functions: print_int and print_string.
The LLVM assembly in add.ll can be converted into executable machine code using the
following steps (also in the shell script run-llvm-code.sh).
llvmconfig=llvm-config
`$llvmconfig --bindir`/llvm-as add.ll # convert LLVM assembly to bitcode
`$llvmconfig --bindir`/llc add.bc # convert LLVM bitcode to x86 assembly
clang add.s decaf-stdlib.c -o add
The binary file add is created and can be run as ./add.
Write down a recursive version of the addition function in LLVM assembly. The following Python program illustrates the algorithm.
def rec_add(a, b):
if a == 0:
return b
else:
return rec_add(a-1, b+1)
The following template illustrates the use of a conditional expression for branching and the use of a recursive function call.
define i32 @add2(i32 %a, i32 %b) {
entry:
%tmp1 = icmp eq i32 %a, 0
br i1 %tmp1, label %done, label %recurse
recurse:
; insert LLVM assembly here
done:
; insert LLVM assembly here
}
It checks whether the first argument to the add2 function is equal to zero
and sets a boolean location %tmp1 to a boolean value (booleans in LLVM are of
type i1 or integer of bit width 1). The br call then branches either to
%done or %recurse based on the value in the boolean condition variable
%tmp1. Extend this template to write the LLVM assembly for recursive
addition.
Simple Recursion
Implement the factorial function in LLVM assembly and print out the value of
11! using print_int.
Introduction to the LLVM C++ API
Headers
Typically include the following LLVM header files which contain the most useful functions in the LLVM API.
llvm/IR/DerivedTypes.h
llvm/IR/LLVMContext.h
llvm/IR/Module.h
llvm/IR/Type.h
llvm/IR/Verifier.h
llvm/IR/IRBuilder.h
It is a good idea to download the source for LLVM and have a look at the
IRBuilder.h header file. It contains almost all the functions that you need
for building the Decaf compiler (they all return a pointer to a sub-class of
llvm::Value).
The Module
The easiest way to collect all the generated code in one place is
to declare a global variable into which you can insert blocks and
function definitions. In the same way, it is convenient to define
a global variable which contains the Builder which is used to
most of the LLVM instructions we need for code generation.
// this global variable contains all the generated code
static llvm::Module *TheModule;
static llvm::LLVMContext TheContext;
// this is the method used to construct the LLVM intermediate code (IR)
static llvm::IRBuilder<> Builder(TheContext);
You can dump the LLVM assembly by calling the print function and
specifying output to standard output outs() or standard error
errs():
TheModule->print(llvm::errs(), nullptr);
LLVM Value
Almost everything in LLVM, including types, constants, functions,
etc. is derived from a base class of llvm::Value.
So if you want to pass a single pointer in your yacc or codegen
code then it is a good idea to use llvm::Value* to pass things
around. You can always cast it back to the appropriate type when
needed. For instance, if you pass a llvm::Value* but you want to
treat it as an LLVM Function then you should cast it back to
llvm::Function *.
LLVM Types
For variables we can create a typed location using the IRBuilder functions
below that return a llvm::Type*
| Type | llvm::Type* |
Explanation |
| void | Builder.getVoidTy() | just a void type |
| int | Builder.getInt32Ty() | assume 32 bit integers |
| bool | Builder.getInt1Ty() | a one bit integer |
| string | llvm::PointerType::getUnqual(Builder.getInt8Ty()) | pointer to array of bytes (int8) |
Here is a helper function that returns the correct LLVM type for each Decaf type:
typedef enum { voidTy, intTy, boolTy, stringTy, } decafType;
llvm::Type *getLLVMType(decafType ty) {
switch (ty) {
case voidTy: return Builder.getVoidTy();
case intTy: return Builder.getInt32Ty();
case boolTy: return Builder.getInt1Ty();
case stringTy: return llvm::PointerType::getUnqual(Builder.getInt8Ty()); default: throw runtime_error("unknown type");
}
}
LLVM Constants
Sometimes the compiler needs to zero initialize a data structure (such as scalars or arrays).
For this you can generate a zero constant using the following LLVM functions which
return llvm::Constant*.
| int32 | Builder.getInt32(0) |
| bool | Builder.getInt1(0) |
Storage on the Stack
In Decaf, we need to store various objects such as variables, arguments to methods during a method call, and a few other objects. In most of these cases, we can store the contents of these variables in stack memory (as opposed to heap memory which requires a malloc). Storing in stack memory is convenient because once the function goes out of scope the memory for those variables is automatically reclaimed.
To create a new location (when the variable is defined) the following
LLVM API call creates an allocated storage location TYPE which
is of type llvm::Type* and returns a pointer to the location name
in LLVM assembly.
llvm::AllocaInst *Alloca = Builder.CreateAlloca(TYPE, 0, NAME);
For example the following code uses the LLVM API to create an alloca
instruction to store integers (LLVM type i32) on the stack. This storage
space is used to store values and to load values from the memory locations on
the stack.
llvm::AllocaInst *Alloca;
// unlike CreateEntryBlockAlloca the following will
// create the alloca instr at the current insertion point
// rather than at the start of the block
Alloca = llvm::Builder.CreateAlloca(llvm::IntegerType::get(TheContext, 32), 0, "variable_name");
You should then store this pointer into the symbol table for the identifier
NAME. You can access the pointer to the type TYPE using
Alloca->getType() when you want to assign a value to this location.
To assign a value in a Decaf statement of the type lvalue = rvalue you should get the location of lvalue from the symbol table. You can check the type of rvalue using the following API call:
const llvm::PointerType *ptrTy = rvalue->getType()->getPointerTo();
And check that the type of the Alloca location for lvalue has the same type:
ptrTy == Alloca->getType()
If the types match then you can assign rvalue to lvalue:
llvm::Value *val = Builder.CreateStore(rvalue, Alloca)
Arithmetic and Boolean Operators
All the binary operators you need for Decaf are defined in the LLVM IRBuilder header file.
+ |
Builder.CreateAdd |
- |
Builder.CreateSub |
* |
Builder.CreateMul |
/ |
Builder.CreateSDiv |
<< |
Builder.CreateShl |
>> |
Builder.CreateLShr |
% |
Builder.CreateSRem |
< |
Builder.CreateICmpSLT |
> |
Builder.CreateICmpSGT |
<= |
Builder.CreateICmpSLE |
>= |
Builder.CreateICmpSGE |
&& |
Builder.CreateAnd |
|| |
Builder.CreateOr |
== |
Builder.CreateICmpEQ |
!= |
Builder.CreateICmpNE |
The unary operators are also defined in LLVM IRBuilder.
- |
Builder.CreateNeg |
! |
Builder.CreateNot |
Method Declaration
A method declaration needs some setup: the name of the function, the return type, and the argument list with the right types. Once you have those, creating a function definition is easy.
llvm::Type *returnTy;
// assign the correct Type to returnTy
std::vector<llvm::Type *> args;
// fill up the args vector with types
llvm::Function *func = llvm::Function::Create(
llvm::FunctionType::get(returnTy, args, false),
llvm::Function::ExternalLinkage,
Name,
TheModule
);
Then you have to create a basic block to hold the instructions for this method.
// Create a new basic block which contains a sequence of LLVM instructions
llvm::BasicBlock *BB = llvm::BasicBlock::Create(TheContext, "entry", func);
// insert "entry" into symbol table (not used in HW3 but useful in HW4)
// All subsequent calls to IRBuilder will place instructions in this location
Builder.SetInsertPoint(BB);
When you generate code for a method declaration do the following:
- Create a new symbol table for local variables
- Create a BasicBlock, let’s say
BB - Do
Builder.SetInsertPoint(BB) - If you have done the function declaration for
Function* functhen iterate through the function arguments usingarg_iteratorand allocate them into the stack for each argument.
Let us consider an illustrative example for one function parameter called a of type int for a Function* func:
string name = string("a");
llvm::Function::arg_iterator AI = func->arg_begin();
AI->setName(name);
llvm::AllocaInst *Alloca = Builder.CreateAlloca(Builder.getInt32Ty(), nullptr, name.c_str());
// Store the initial value into the alloca.
Builder.CreateStore(static_cast<llvm::Value *>(&*AI), Alloca);
// Add to symbol table
syms.enter_symtbl(name, Alloca);
You will have to iterate through each of the arguments in the method declaration AST and use the name and type and add it to the function definition using the arg_iterator as shown below.
You need to name and load each argument from the function before running code generation on the body, so they can be used in the body statements. Iterate through each argument using an iterator, set the names, allocate them, and store them. This process is unique to generating function parameters.
for (auto &Arg : func->args()) {
llvm::AllocaInst *Alloca = CreateEntryBlockAlloca(func, Arg.getName());
// Store the initial value into the alloca.
Builder.CreateStore(&Arg, Alloca);
// Add to symbol table
syms.enter_symtbl(Arg.getName(), Alloca);
}
You can get useful information about the method including a pointer to the function definition itself by using the following functions:
llvm::BasicBlock *CurBB = Builder.GetInsertBlock();
// gives you a link to the current basic block
llvm::Function *func = Builder.GetInsertBlock()->getParent();
// gives you a pointer to the function definition
func->getReturnType()
// gives you the return type of the function
To create a return statement you first need to recover the function and then insert a return statement:
// sometimes the return statement is deep inside the method
// so it is useful to retrieve the function we are in without
// passing it down to all the AST nodes below the method declaration
Builder.CreateRet(llvm::Value*)
You should create a default return type when you create the function definition. You can replace it with the real return if there is one but by default you should return the default value for the method return type (zero for integers, and true for booleans).
The following function with an appropriate enum definition of
decafType will provide you the default value for the method return
type:
typedef enum { voidTy, intTy, boolTy, stringTy, } decafType;
llvm::Constant *getZeroInit(decafType ty) {
switch (ty) {
case intTy: return Builder.getInt32(0);
case boolTy: return Builder.getInt1(0);
default: throw runtime_error("unknown type");
}
}
Method Calls
Code generation for a method call also requires some setup.
llvm::Function *call;
// assign this to the pointer to the function to call,
// usually loaded from the symbol table
std::vector<llvm::Value *> args;
// argvals are the values in the method call,
// e.g. foo(1) would have a vector of size one with value of 1 with type i32.
bool isVoid = call->getReturnType()->isVoidTy();
llvm::Value *val = Builder.CreateCall(
call,
args,
isVoid ? "" : "calltmp"
);
In the above code fragment, the location calltmp is used to store
the value returned by the method call.
Promoting a boolean
You can promote a boolean of type i1 to an integer using ZExt:
llvm::Value *promo = Builder.CreateZExt(*i, Builder.getInt32Ty(), "zexttmp");
Remember to do this in method calls (e.g. to print_int) if there is a type mismatch.
Global String Variables in LLVM
You can declare a global variable in LLVM as follows:
llvm::GlobalVariable *GS = Builder.CreateGlobalString(s, "globalstring");
llvm::Value *stringConst = Builder.CreateConstGEP2_32(GS->getValueType(), GS, 0, 0, "cast");
Verification
You can ask LLVM to verify your function declaration (should be of type llvm::Function):
llvm::verifyFunction(F);
LLVM and Yacc: Simple Arithmetic Expressions
Before you do this practice problem, make sure you have a working symbol table implementation as specified in HW3.
The following yacc program fragment does code generation using the LLVM API.
The full source code is available in the file sexpr-codegen.y.
%union{
class ExprAST *ast;
int number;
}
%token <number> NUMBER
%type <ast> expression
%%
statement: expression
{
Value *RetVal = $1->Codegen();
Function *print_int = gen_print_int_def();
Function *TheFunction = gen_main_def(RetVal, print_int);
verifyFunction(*TheFunction);
}
;
expression: expression '+' NUMBER
{
$$ = new BinaryExprAST('+', $1, new NumberExprAST($3));
}
| expression '-' NUMBER
{
$$ = new BinaryExprAST('-', $1, new NumberExprAST($3));
}
| NUMBER
{
$$ = new NumberExprAST($1);
}
;
%%
It takes simple expressions like 2+3-4 and produces LLVM assembly as output.
declare i32 @print_int(i32)
define i32 @main() {
entry:
%calltmp = call i32 @print_int(i32 1)
ret i32 0
}
It does this by extending your code for building an abstract syntax tree (AST). For example, binary expressions are represented as the following AST data structure:
/// BinaryExprAST - Expression class for a binary operator.
class BinaryExprAST : public ExprAST {
char Op;
ExprAST *LHS, *RHS;
public:
BinaryExprAST(char op, ExprAST *lhs, ExprAST *rhs)
: Op(op), LHS(lhs), RHS(rhs) {}
virtual Value *Codegen();
};
The code is then generated from the AST by calling functions defined in the LLVM API. Two main data structures contain the LLVM assembly code:
static Module *TheModule;
static LLVMContext TheContext;
static IRBuilder<> Builder(TheContext);
int main() {
// Make the module, which holds all the code.
TheModule = new Module("module for very simple expressions", TheContext);
// parse the input and create the abstract syntax tree
yyparse();
// Print out all of the generated code to stderr
TheModule->print(errs(), nullptr);
exit(0);
}
The generated code is produced as a pointer to a data structure
called Value. For example the following function is
used to generate code for binary expressions.
Value *BinaryExprAST::Codegen() {
Value *L = LHS->Codegen();
Value *R = RHS->Codegen();
if (L == 0 || R == 0) return 0;
switch (Op) {
case '+': return Builder.CreateAdd(L, R, "addtmp");
case '-': return Builder.CreateSub(L, R, "subtmp");
}
}
Extend the code provided to you in sexpr-codegen.y in order
to handle LLVM code generation for the following grammar:
statement_list: statement ';' statement_list
| /* empty */
;
statement: NAME '=' expression
| NAME '(' expression ')'
;
expression: expression '+' NUMBER
| expression '-' NUMBER
| expression '+' NAME
| expression '-' NAME
| NUMBER
| NAME
;
It should accept input like the following:
a=2+3;
b=5-2;
c=a+b;
print_int(c+2);
And produce LLVM assembly:
; ModuleID = 'module for simple expressions'
source_filename = "module for simple expressions"
define i32 @main() {
entry:
%a = alloca i32
store i32 5, i32* %a
%b = alloca i32
store i32 3, i32* %b
%a1 = load i32, i32* %a
%b2 = load i32, i32* %b
%addtmp = add i32 %a1, %b2
%c = alloca i32
store i32 %addtmp, i32* %c
%c3 = load i32, i32* %c
%addtmp4 = add i32 %c3, 2
%calltmp = call i32 @print_int(i32 %addtmp4)
ret i32 0
}
declare i32 @print_int(i32)
You will need to use your symbol table implementation to store the location of the variables. 1
Global Variables
In the llvm-practice directory of the compiler-class-hw repository you
can find two example C++ programs: globalscalar.cc and globalarray.cc
for global scalar variables and global array variables respectively.
globalarray.cc also shows you how to access a particular array location, e.g.
Foo[8] and also shows you how to update an array location, e.g. Foo[8] =
Foo[8] + 1.
Kaleidoscope language
The LLVM download comes with a simple programming language which
is illustrative of the LLVM API. In the llvm-practice directory
of the compiler-class-hw repository you can find the toy.cc and
kscope.cc files which contains the entire source code for the
Kaleidoscope compiler and a toy version as well. The compiler uses
LLVM for code generation. Example Kaleidoscope programs are available
in the directory kscope-programs.
Array Types
The LLVM array type is llvm::ArrayType which is provided using the
following function:
llvm::ArrayType::get(TYPE, SIZE)
where TYPE is an LLVM Type and SIZE is the array size.
Control flow graphs
Consider the following function definition that involves control flow using an
if statement.
// function that computes the greatest common divisor
func gcd(a int, b int) int {
if (b == 0) {
return(a);
} else {
return(gcd(b, a % b));
}
}
Below is the desired LLVM assembly output for the above function. To implement control flow and loops we need to set up various basic blocks and link them together using branching statements.
define i32 @gcd(i32 %a, i32 %b) {
entry:
%a1 = alloca i32
store i32 %a, i32* %a1
%b2 = alloca i32
store i32 %b, i32* %b2
br label %ifstart
ifstart: ; preds = %entry
%b3 = load i32, i32* %b2
%eqtmp = icmp eq i32 %b3, 0
br i1 %eqtmp, label %iftrue, label %iffalse
iftrue: ; preds = %ifstart
%a4 = load i32, i32* %a1
ret i32 %a4
br label %end
end: ; preds = %iffalse, %iftrue
ret i32 0
iffalse: ; preds = %ifstart
%b5 = load i32, i32* %b2
%a6 = load i32, i32* %a1
%b7 = load i32, i32* %b2
%modtmp = srem i32 %a6, %b7
%calltmp = call i32 @gcd(i32 %b5, i32 %modtmp)
ret i32 %calltmp
br label %end
}
In the LLVM assembly above we have five different basic blocks. We have already covered how to create a basic block and set an insert point for the instructions that should go into that basic block.
The following diagram graphically shows how the different basic blocks are connected to each other.
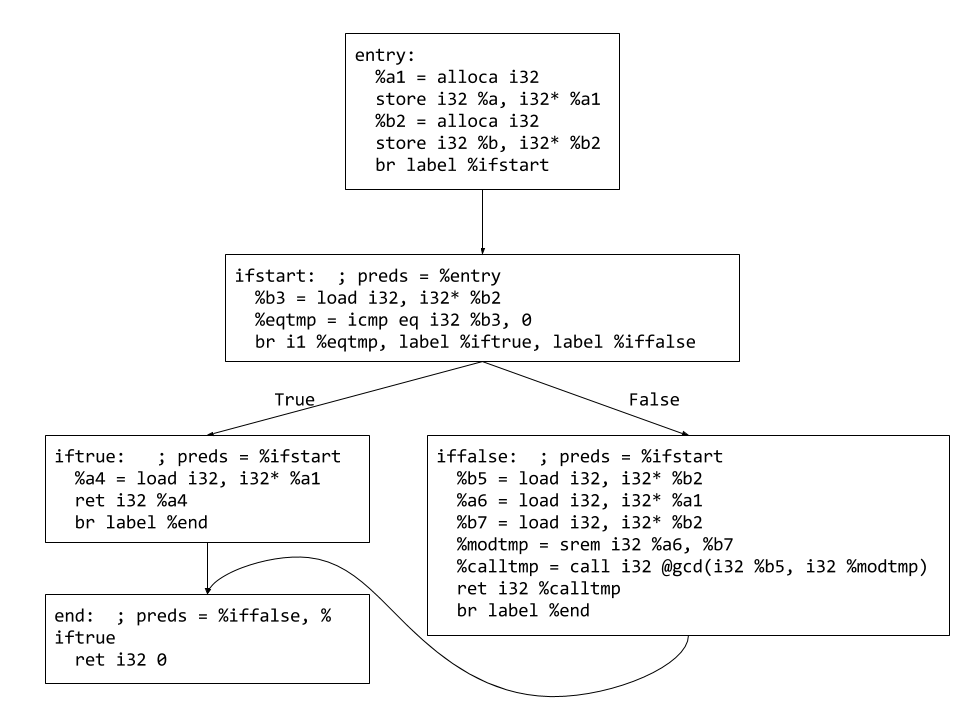
Once you can create basic blocks and insert instructions for each basic block then all that remains is to link them together using unconditional branches and conditional branches using LLVM API calls.
If I have created a basic block llvm::BasicBlock *IfTrueBB (the label
used for this basic block is iftrue in the above LLVM assembly).
Now I want to connect it to the return basic block llvm::BasicBlock *EndBB
which has label end. In order to do this I need an unconditional branch
from IfTrueBB to EndBB which I can do using the following LLVM API
call assuming that my insert point is still in IfTrueBB:
Builder.CreateBr(EndBB)
For the conditional branch from a basic block llvm::BasicBlock *IfBB with
label ifstart to llvm::BasicBlock *IfTrueBB when the conditional statement
evaluates to True or to EndBB when False.
Builder.CreateCondBr(val, IfTrueBB, EndBB)
In this statement, val is an LLVM type i1 (in other words a boolean).
If val is True the branch will go to IfTrueBB and if it is False
the branch goes to EndBB. In the above LLVM assembly the value of
val is stored in %eqtmp.
Backpatching
To implement backpatching for control flow and loops you need to remember
different basic blocks. For example, to implement a for loop you will need to
know the locations of the init, check and post parts of the for loop. The
easiest way to remember this is to save a pointer to the basic blocks in the
symbol table. The symbol to use is the symbol you use to name the LLVM basic
blocks (ifstart, iffalse, and end in the above example). Because the
symbol table already handles nested scopes you do not need to do anything
special to handle any number of deeply nested control flow and loops (like, for
example, nested for loops).
Once you have these basic blocks accessible using the symbol table it becomes
trivial to implement break and continue.
Short Circuit for Boolean Expressions
To implement short circuit for boolean expressions you will need to set
up basic blocks in a way similar to control flow statements like the
if statement. Instead of generating the && and || equivalent
statements in LLVM assembly you have to generate control flow for
short circuiting for && and ||.
The underlying representation for LLVM assembly is in static single assignment form or SSA Form. In SSA Form, each variable is only assigned a value once in the program. The value of the variable can be used multiple times. In complex control flow graphs a variable might get a value from two different paths in the program. To deal with this complexity, SSA Form uses the concept of a \(\phi\) function which creates a new variable which depends on which path was taken through the control flow graph.
For short circuit of boolean expressions you have to create the \(\phi\) function yourself.
llvm::PHINode *val = Builder.CreatePHI(TYPE, 2, "phival");
where TYPE is an LLVM::Type
A \(\phi\) function is created using the LLVM function CreatePHI:
llvm::PHINode *val = Builder.CreatePHI(L->getType(), 2, "phival");
val->addIncoming(L, CurBB);
val->addIncoming(opval, OpValBB);
where L is the LLVM output for the LHS of the boolean expression and CurBB
and OpValBB are the two basic blocks that are incoming blocks for the
\(\phi\) function.
RTFM: LLVM Documentation
There is a lot more to learn about LLVM. Read the documentation at llvm.org.
-
The s-expr practice solution. You need a working symbol table in
symboltable.ccwith the functionsnew_symtblandremove_symtblto add/remove symbol tables as well asaccess_symtblandenter_symtblto read/write to the symbol table. Please do the exercise yourself before viewing the solution. ↩