
Homework 0: Setup
Start on May 15, 2023 | Due on May 29, 2023
Setup on Coursys
Find a group to work with for the homework assignments and the final course project. The group size is 3 people or less. We will be checking that all group members are contributing equally to the homework submission and the final project.
Along with your group members, register yourself as part of a group on Coursys.
Create a memorable name for your group. If you need help, seek help. Make sure there is no whitespace in your group name or anything that might cause a mojibake (please use plain ascii).
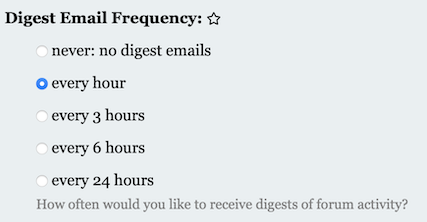
Go to the Course Discussion Page and select [Activity Digest].
Change the Digest Email Frequency: to a setting that send you email notifications, like so:
Setup Git Repository
Git Basics
In this course, your programs will be managed and archived using Git. The basic idea is as follows:
- Every student and group gets a private storage area called a repository on the SFU server machines, or “repo” for short.
- Your code is stored in your repo. Every time you make a change to your code, you commit a new revision of your code to the repo for permanent storage. All revisions you ever commit are kept, and you can retrieve any committed revision any time. This means you have a combined backup and means to undo any changes you ever make. This is how software engineers manage their code projects.
Create new repository on Gitlab
Decide in your group the person that will create the repository on GitLab and invite the other group members as a Maintainer. That person should follow the instructions in this section.
Go to the SFU Gitlab server which is on the web at gitlab.cs.sfu.ca. Log in with your SFU username and password, the same one you use to check your e-mail on SFU Connect.
Once logged in, you will see a list of your existing repos if you
have created any in the past. Create a new repository for this class
by clicking the New Project button at the top right of the page.
On the New Project page, select Create a Blank Project and then
give your repo a name under the Project name field. The default
name is my-awesome-project which is not what you should call
your repo. Instead, name your repo: advnlpclass-1234-g-GROUP where GROUP is the group you registered on Coursys. For example, a repository name might be advnlpclass-1234-g-ethicsgradient Make sure you add the g- before
your group name. It’s important to name the repo exactly as you see
here.
Do not use any obscene words in your group name. Be mature about your choice of group name. That does not mean it cannot be funny, just be aware that your choice of group name may offend someone else so be considerate of others.
Leave all other settings as they are and click the Create Project button
at the bottom left of the page.
Make sure you do not change the default setting of Private. Your
repo must be visible only to yourself and your group members
You must not give access to your repo to any other students except your group members.
Plagiarism is a serious academic offense.
Your repo has now been created. You will be taken to a web page for your newly created repo.
Add the instructor and TA as Developers
This is the most important step in the setup of your GitLab repository
The course instructor and the TAs need access to your repo in order to test
and grade your code. Add the instructor and TAs as a member of your
repo by clicking on the Settings menu and choosing Members which looks like this:

On the page that loads up type in (or individually copy/paste) the
following list of names in the Add new user box using a , to
delimit each username: anoop,sshavara,hushah,Change the role permissions from Guest to Developer in the
dropdown menu. Click on Add to Project to add the instructor and
all TAs as Developers to your github repo.
Set up notifications
Next you should set up notifications about Issues in your repository.
Go to User Settings from the upper right corner menu. Select
Preferences menu which should take you to User Settings where
you can select Notification where you should pick the Global
notification level to Watch and also select Receive notifications
about your own activity. You can also set notifications specifically
for your repository to Watch.
Setup SSH Key
Next we will set up the Secure Shell (ssh) keys so you can access your repo without a password. First follow the instructions on setting up your SSH key pair available at csil-git1.cs.surrey.sfu.ca/help/ssh/README. Follow the instructions for Linux.
Now we have to copy your public key to the GitLab server.
The instructions ask
you to use xclip which may not be installed on all the CSIL machines.
If you cannot find xclip (“Command not found”) then do the
following steps
If you have set up your SSH key correctly then you will have a public key. View it
cat ~/.ssh/id_rsa.pub
This will show you the public key. Use the Terminal copy command to copy
this into your clipboard.
Then go to this page:
csil-git1.cs.surrey.sfu.ca/profile
and select SSH Keys from the left menu.
Use the web browser to paste command to paste your public key into the Key
box and give it a Title (e.g. ‘CSIL’ is a reasonable title) and then Add key.
Clone your Repository
Download a copy of your repo to your CSIL machine. The action of making a local copy of your online repo is known as a “clone”.
In the terminal window, enter the commands
git config --global user.name USER
git config --global user.email USER@sfu.ca
git config --global core.editor nano # or set it to your favourite editor
git config --global push.default current
cd $HOME
git clone git@csil-git1.cs.surrey.sfu.ca:GROUPUSER/advnlpclass-1234-g-GROUP.git
where USER is your SFU username, GROUPUSER is the SFU username of
the person who created the group repository and GROUP is the name of the
group you have already setup on Coursys. If
you skipped any of the above steps in setting up your GitLab repo
this command will not work. The system might prompt you for a
username/password combo. Supply the usual answers. To avoid entering
your username/password over and over again you can set up passwordless
ssh.
Your repo will be cloned into a new directory (also known as a folder)
called advnlpclass-1234-g-GROUP.
Create your Homework 0 directory
After cloning your repository, make sure you are inside your repository and at the top level. Create a directory for Homework 0:
mkdir hw0
cd hw0
pwd
When you print your working directory it should look like this:
advnlpclass-1234-g-GROUP/hw0
Add a file README.md to this directory using your favourite editor
and then git add README.md and git commit -m "Initial hw0 commit"
and then git push to send your new directory and file to the
GitLab server. Open up GitLab on a web browser to check that you
can see hw0/README.md in your repository on the web browser.
Add a .gitignore file at the top level of your git repository
to avoid committing and pushing useless files to the GitLab
server. Here is a typical .gitignore file.
venv
__pycache__
.DS_Store
*.egg-info
.ipynb_checkpoints
Python 3 Notebooks
We will be using Python 3 notebooks for development, but you will be submitting a self contained Python 3 program that can be run on the command line as well.
First set up a virtual environment to contain all the dependencies you need to run a Python3 notebook. To use virtualenv to manage dependencies, first setup a virtualenv environment:
python3 -m venv venv
source venv/bin/activate
pip3 install -U -r requirements.txt
The file requirements.txt should minimally have the following
contents.
pip
wheel
notebook
jupyter_contrib_nbextensions
jupyter_nbextensions_configurator
You can add more requirements by creating your own requirements.txt
file in the answer directory of each homework. Typically for
each homework you will add any additional software package requirements
you need into the requirements.txt file. These packages should
be already available on CSIL machines so the venv should not use
up too much disk space if you are using a CSIL machine.
If you have trouble, sometime clearing the pip cache helps. Remove
the contents of ~/.cache/pip before the pip install.
Run jupyter notebook:
jupyter notebook
Read the jupyter documentation and get used to editing a notebook with a combination of markdown and Python code.
Task: Spell Checking
The task for this homework is to do contextual spell checking for English.
Homework 0 is mainly to set up your groups and programming environment for this course for the semester, but to complete this homework you have to submit the solution to the following task as your submission for Homework 0. It will serve as a guide for the steps to be taken for all subsequent homeworks in this course.
Submission for each homework will be done on Coursys.
Getting Started
Get started:
git clone https://github.com/anoopsarkar/nlp-class-hw.git
cd nlp-class-hw/spellchk
Clone your repository if you haven’t done it already:
git clone git@csil-git1.cs.surrey.sfu.ca:USER/advnlpclass-1234-g-GROUP.git
Then copy over the contents of the spellchk directory into your
hw0 directory in your repository.
Set up the virtual environment:
python3 -m venv venv
source venv/bin/activate
pip3 install -r requirements.txt
Note that if you do not change the requirements then after you have
set up the virtual environment venv you can simply run the following
command to get started with your development for the homework:
source venv/bin/activate
Background
Given a sentence with a typo in it:
it will put your maind into non-stop learning.
The task is to correct the typo word maind to the most plausible
substitution, e.g.:
it will put your mind into non-stop learning.
There are many ways to solve this problem but we are going
to use a large language model to solve this task. We will
take the typo word and replace it with a [MASK] token
and ask the language model to suggest the most plausible
token it could be. Because the language model has been
trained on a lot of English data, it is able to capture
the semantic meaning of what should be in the [MASK]
position and use that to predict a token that fits in
this sentence.
Since this task is part of a setup homework, we will simplify the task and include the indices of the typo words in the sentence, so the words to be replaced with the correct words have been provided to you.
The input contains a comma separated list of token indices followed by a tab character and followed by the sentence with at least one typo in it.
Here is an example input:
0,3 thier house was father away from my place
The typo words are in position 0 (thier) and 3 (father). Notice
how the typo words can be found in a dictionary, so just using a
number of edits away from a dictionary word is not an approach that
will work for this task.
The input will be a file of such inputs with locations of the typos and the sentence. The output should also include the locations indices:
0,3 their house was farther away from my place
We have provided a default solution for this task and all the mechanisms for running your solution on two sets of data: dev and test data. The answers for dev data are provided, but the answers for test data are not distributed.
Default solution
The default solution is provided in default.py. To use the default
as your solution:
cp answer/default.py answer/spellchk.py
cp answer/default.ipynb answer/spellchk.ipynb
python3 zipout.py
python3 check.py
Make sure that the command line options are kept as they are in
default.py. You can add to them but you must not delete any
command line options that exist in default.py.
The default solution uses a large language model from the transformers
library by huggingface and a mask token
replacement task which is a task used to train the language model
on Wikipedia and the Books corpus.
Here is how the default solution uses the recommended language model to solve this task:
from transformers import pipeline
fill_mask = pipeline('fill-mask', model='distilbert-base-uncased')
mask = fill_mask.tokenizer.mask_token
print(fill_mask(f"it will put your {mask} into non-stop learning.")[0])
This will produce the output:
{
'score': 0.11389569193124771,
'token': 2568,
'token_str': 'mind',
'sequence': 'it will put your mind into non - stop learning.'
}
In this case, the output is correct, but the most plausible substitution is not always the best candidate for a correction.
Use the distilbert-base-uncased language model for this
homework.
The Challenge
Your task is to improve the accuracy on this task as much as possible. The definition of accuracy is provided below. You cannot use any external data sources. You can use a Python 3 library that provides some helper functions but not any spelling correction modules or any other spelling correction models.
You can get a much higher accuracy by changing the function
select_correction with 1-2 lines to take into account something
that isn’t taken into account by the default solution. Even
though, it is 1-2 lines, the solution may not be obvious or
trivial.
You should approach this challenge based on a careful examination of the source code of the default solution and the output of the default solution on the various inputs.
Data files
The data files provided are:
data/input– input filesdev.tsvandtest.tsvdata/reference/dev.out– the reference output for thedev.tsvinput file
Required files
You must create the following files:
answer/spellchk.py– this is your solution to the homework. start by copyingdefault.pyas explained below.answer/spellchk.ipynb– this is the Python notebook that will be your write-up for the homework.
Run your solution on the data files
To create the output.zip file for upload to Coursys do:
python3 zipout.py
For more options:
python3 zipout.py -h
Check your accuracy
After you have run zipout.py you can check your accuracy on the
dev set:
python3 check.py
The score reported is the accuracy of getting the typo word corrected to the right token in the reference file.
For more options:
python3 check.py -h
In particular use the log file to check your output evaluation:
python3 check.py -l log
The accuracy on data/input/test.tsv will not be shown. We will
evaluate your output on the test input after the submission deadline.
First run zipout.py to get the output.zip file.
$ python3 zipout.py -r default.py
Warning: output already exists. Existing files will be over-written.
running on input data/input/dev.tsv
running on input data/input/test.tsv
output.zip created
Once you have output.zip you can run the scorer. The default
solution gets a very poor accuracy on the dev and test set:
$ python3 check.py
dev.out score: 0.27
test.out score: 0.20
Using a single line function added to the default solution with no change to the input data files should get you remarkably higher accuracy on both dev and test:
$ python3 check.py
test.out score: 0.56
dev.out score: 0.65
Submit your homework on Coursys
Once you are done with your homework submit all the relevant materials to Coursys for evaluation.
Create output.zip
Once you have a working solution in answer/spellchk.py create
the output.zip for upload to Coursys using:
python3 zipout.py
Create source.zip
To create the source.zip file for upload to Coursys do:
python3 zipsrc.py
You must have the following files or zipsrc.py will complain about it:
answer/spellchk.py– this is your solution to the homework. start by copyingdefault.pyas explained below.answer/spellchk.ipynb– this is the Python notebook that will be your write-up for the homework.
In addition, each group member should write down a short description of what they did for this homework in the Python notebook.
Upload to Coursys
Go to Homework 0 on Coursys and do a group submission:
- Upload
output.zipandsource.zip - Make sure you have documented your approach in
answer/spellchk.ipynb. - Make sure each member of your group has documented their contribution to this homework in the Python notebook.
Grading
The grading is split up into the following components:
- Group setup done on Coursys.
- GitLab setup including adding instructor and TA as Developer to the repository.
- dev scores (see Table below)
- test scores (see Table below)
- Python notebook write-up
- Check if each group member has written about what they did in the Python notebook.
Your accuracy should be equal to or greater than the scores listed for dev and test data to obtain the corresponding marks (dev and test sets are marked separately).
| dev accuracy | test accuracy | Marks | Grade |
| .02 | .00 | 0 | F |
| .09 | .00 | 55 | D |
| .16 | .07 | 60 | C- |
| .23 | .14 | 65 | C |
| .30 | .20 | 70 | C+ |
| .37 | .28 | 75 | B- |
| .44 | .35 | 80 | B |
| .51 | .42 | 85 | B+ |
| .58 | .49 | 90 | A- |
| .65 | .56 | 95 | A |
| .72 | .63 | 100 | A+ |
The score will be normalized to the marks on Coursys for the dev and test scores.